General Intro to NLP
This lecture introduces the field of NLP and presents basic descriptive linguistic concepts: levels of description, word-level description, syntactic description of sentences.
What is NLP about
Different names - refer to different perspectives on language:
- Natural Language Processing
- Computational Linguistics
- Human Language Technologies
In general, it is important to distinguish the main motivation to study the field:
- Engineering: useful tasks involving text (Information Retrieval, Machine Translation, Summarization, Report Generation)
- Scientific: understand language (what it is, how it is used, produced and understood, how it is learned, how it evolves over time) using computational models
Different computational/descriptive methods have been used to model language:
- Knowledge-based methods: rely on symbolic knowledge representation (lexicon, grammar, semantic structures and inference rules)
- Statistical methods: rely on statistical models, machine learning and large collections of data. Probabilistic inference.
Natural languages are instances of a more general category of phenomena called "signs" studied in the field of semiotics.
A key definition of semiotics is to study the relation between "signs" and "meaning" that people attribute to them.
The basic distinction between signifier and signified was introduced by De Saussure (Cours de Linguistique Generale, 1916).
These two aspects are also called expression and content.
See Semiotics for Beginners by Daniel Chandler for an introduction to the key concepts of semiotics (signifier, signified, sign, arbitrariness, structuralism, contrastive relation, syntagm and paradigm, type/token distinction).
The various perspectives on the field (NLP, CL, HLT) must pay attention to key aspects of language:
- Ambiguity (relation 1-n between signifier and signified)
- Variability (relation 1-n between signified and signifiers)
- Vagueness (the fact that a specific signifier may relate simultaneously to multiple signified items)
- Structure (the internal structure of signifiers)
- Conventionality: arbitrary agreement on signifier/signified relation (no "natural" or "motivated" relation between signifier and signified)
- Non-categorical phenomena (non-binary, gradual decisions) [what is grammatical, what is a word, what is meaningful, what is a noun, what is a verb etc.]
- Relation to cognition: meaning, communication, experience [what is more likely to "make sense", what is the expected structure of the signified world]; related to other cognitive phenomena [memory, learning, vision, planning]; can non-embodied agents produce / understand language in a meaningful manner.
Ambiguity in Language
Key observation: (Practically) infinite occurrences (language = set of possible sentences) / finite processing (cognitive system with limited resources can generate and process unseen sentences in the language).
One way to explain this cognitive capability is that language relies on structure (and recursion).
Text is structured, but structure is not manifest.
Therefore, problems of ambiguity (determining the intended structure).
There are different sources of ambiguity in language:
- Lexical: bank (river/financial)
- Morphological: books (book(N)+plural) vs. (book(V)+present+singular+third person
- Syntactic: I see a man on the hill with a telescope / (I am on the hill vs. the man is on the hill)
- Semantic: Every man loves a woman (scope of the quantifier - one universal woman vs. one woman per man)
- Pragmatic: Can you pass the salt (Do you have the ability of passing the salt (Yes-no question) vs. request to pass the salt)
Local vs global ambiguity / multi-layer combination of ambiguities:
Key computational challenge: classify occurrences of signs according to signified properties.
Variability in Language
Key observation: there are many different ways to express the same meaning in language.
- Lexical:
- book, volume, document, best-seller, publication... (synonyms)
- X causes Y vs X is the cause of Y vs. X leads to Y vs. X triggers Y
- the book deals with Linguistics vs. the book is about linguistics
- Syntactic: Syntactic alternations
- the cat eats the mouse vs. the mouse is eaten by the cat (active vs. passive)
- John gives Mary a book vs. John gives a book to Mary (dative move)
- John gives a book about Linguistics to Mary vs. John gives to Mary a book about linguistics (heavy NP shift)
- Referential: when refering to a table in a room:
- The table
- The piece of furniture in the left corner
- The table next to which I am standing (if there are more than one table)
- it
- this
- that
- Stylistic: Raymond Queneau: Exercises in Style (99 ways to retell the same story in different styles).
Variability makes it difficult to assess whether 2 distinct linguistic
forms are actually similar in meaning. It makes it difficult to find
text based on meaning, and it makes it difficult to decide how to
generate text given meaning representation (or similar text).
Altogether - combination of variability leads to the possibility for "paraphrases" - many different ways to express the same meaning in different sentences.
Determining whether 2 sentences are paraphrases is a non-categorical judgment (gradable - sentences may be more or less similar).
Key computational challenge: compute similarity of signs.
Vagueness in Language - Non-categorical Judgments
Vagueness is the property that a specific instance of a signifier may refer simultaneously to more than one signified item (in the same occurrence).
- Vagueness vs. Ambiguity
- Vagueness vs. Generality
- Vagueness in the described object
Non Categorical Phenomena in Language
Many of the tools used to describe language are defined as discrete categorical judgments.
For example, we find it useful to distinguish between Nouns and Verbs.
It is, however, often useful to refer as these descriptive categories as non-categorical gradual classifications.
A good example is discussed in this Video presentation
by Chris Manning at ACL 2015 (seek at position 24:00 for this specific discussion) which is
also summarized in Computational Linguistics and Deep Learning (see in particular Section 5).
In the discussion of Verb vs. Noun categories, consider the English Gerund V-ing form, such as climbing.
Classically such forms are described as ambiguous alternations between nominal / verbal forms.
V-ing can take any of the core categories defined by Chomsky 1970:
(4-way classical POS distinction)
+N / +V an unassuming man [Adj]
+N / -V the opening of the store [N]
-N / +V she is eating dinner [V]
-N / -V concerning your point [Prep]
But it seems the membership of V-ing forms to N or V is more than "ambiguity": it is more appropriate to relate to it as "non categorical membership to V/N classes".
Consider the following criteria (test) that determine whether a specific word form belongs to N or V:
- Noun: appears with determiner
- Verb: appears with direct object
One can find occurrences of V=ing that satisfy both criteria at once:
The not observing this rule is damaging to our reputation.
It appears the V-ing are not simply ambiguous (can be sometimes V and sometimes N depending on context)
but instead hold an intermediate status different from true nominalizations - V=ing forms have in-between status
which is not the case for N or V forms:
Tom's winning the election was a big upset
? This teasing John all the time has got to stop
? There is no marking exams on Fridays
* The cessation hostilities was unexpected
We refer to such judgments as "non categorical facts" that can be modeled mathematically as fuzzy membership to the categories.
In computational terms, instead of representing membership to the Part-of-speech category N or V as a categorical data for a
given word form {N:1, V:0}, we can represent the judgment by using a probability distribution that reflects the relative properties of the
word form {N:0.7, V:0.3}. Naturally, we will need to work out criteria to explain where these exact numbers come from and what depends on them.
Recent work on deep learning applied to NLP has taken this computational approach.
Discrete and Sparse Data
Written language is built from discrete symbolic units (letters, words). These small units are composed into
larger structures (mainly using sequential composition).
This makes the study of language very different from for example research in Vision which deals with continuous, 3D structures and their properties (color, texture, geometry, transparency).
The discrete/symbolic nature of language combined with the arbitrariness of the signifier/signified relation makes
the study of "similarity in language" and "relatedness" challenging. For example, we "feel" that the expressions "light blue" and "turquoise" are "close in meaning" because they refer to colors which are "close in perceptual quality". But there is no similarity in the sequences of letters that are used to make these expressions that hints to this similarity in meaning.
In order to hope to grab such similarity relations, we must rely on the analysis of occurrences of the expressions
in larger documents. This approach (often called the "distributional hypothesis") assumes that two
expressions have similar meaning if they occur in similar contexts.
The computational problem that this type of analysis is that is suffers from the problem of data sparseness:
the combinations of letters into long sequences yields exponentially many sentences and documents.
Even with web-scale document collections, it is frequent to find expressions that occur little (less than 10 times
in collections of billions of words).
The other problem that discrete data leads is that it is difficult to approximate or generalize decisions on textual data because the data is not "continuous". (Think of the analogy of learning one-way functions such as
turning a color picture into a black-and-white version and the inverse function -
see this colorization demo).
Levels of Linguistic Description
Language use can be described at various levels - corresponding to different internal structures in language:
- Discourse: text structure, conversation structure
- Sentence: syntax
- Lexical: words, word structures, relations among words within a dictionary
- Phonologic: sound structure
- Letters
It can also be described from various perspectives - corresponding to
different functions language fulfils:
- Textual: what are the relations of different text spans with other
textual spans (repetition, reference, citation, allusion) and within a
given textual unit, how do sub-units relate to each other
(syntax).
- Inter-personal: Communication, what is achieved by using
language between speakers, writer/reader relation (convey information, request information or service, persuade, mark distinction...).
- Content: relation between text and the world language describes.
These various levels are studied by different sub-disciplines in
linguistics:
- Morphology
- Syntax
- Pragmatics
- Semantics
Words: Parts of Speech and Morphology
Syntactic analysis starts with the following questions:
- What is a word? (basic terminal unit in the parse tree) / Issues in tokenization.
- What is a sentence? (top level unit in the parse tree) / Sentence delimitation.
- What are the basic properties of words
We first focus on the word level. There are various definitions of what is a word:
- Graphic: a sequence of letters surrounded by delimiters (issues: what are delimiters)
- Phonetic: a sequence of sounds surrounded by silence (issues: what is a phonetic delimiter, are all words really separated by silence)
- Semantic: an independent unit of meaning (issues: non-compositional word compounds, semantically empty words)
- Morphological: a structural unit composed of a least one base morpheme and decomposable into morphemes (issues: can morphemes appear independently of base morpheme, what are morphemes)
- Syntactic: a constituent which can be the head of a lexical phrase
- Dictionary-based: a unit that is listed in the "lexicon" of a language (issues: ignore change in language over time, dialects)
Words have an internal structure - they are composed of smaller parts
that have grammatical function (mark number, gender, person, tense
etc).The parts of words that have meaning are called morphemes.
Linguists define groups of words which "behave in a similar manner" in
syntactic contexts. The basic test is substitution.
A set of signs where one unit is substituted by another and the other is kept constant forms a paradigm.
For example:
abstract-ly
concrete-ly
definite-ly
is a morphological paradigm (illustrating English adverb derivation).
Similarly:
I sing
You sing
He sing-s
We sing
You sing
They sing
is also a paradigm (illustrating the person property for English verbs).
The comparison of paradigms allows structuralist linguists to identify morphemes and word formation processes.
Basic classes are: verb, noun, adjective. These are called parts of speech.
For basic Parts of speech we can provide a semantic interpretation:
- verb: action or state
- noun: entity (people, concepts, things)
- adjective: property
It is important to distinguish open and closed classes, because they have very different properties:
- Open-class (many members, new members often added)
- Closed-class (few members, functional use): article, preposition... - very stable over time.
Morphological features:
- Features of words: number, gender, tense, person, case; Note that relevant features depend on the word class (different features for nouns and verbs for example).
- Processes: Inflection, derivation, compounding.
There exist different types of morphological processes that can combine new word forms from basic word forms:
- Inflection is the process of modifying a root form by combining prefixes and suffixes to indicate the presence of morphological features.
- Derivation is the process of creating a new lexical item from an existing, more basic one. For example, the derivation of the noun of
action destruction from the verb destroy, or the chain of derivations luck/noun, lucky/adjective, luckily/adverb.
- Compounding is the process of combining several lexical items into a new one, whose properties can be derived from the compounded elements,
or can be independent. For example, in Hebrew beit sefer is derived from bayit and sefer and behaves as a compound (smixut)
in a way different than can be predicted from each unit separately (non-compitional compound).
The mechanisms of morphological transformation include:
- Prefix and suffix attachment (for example, add an "s" at the end of nouns to mark plural)
- Internal change (for example: sing -> sang).
Inflections mark morphological features in the word. The set of relevant features depends on the word class:
- Noun: number, gender, [possessive marker]
- Pronoun: number (he/they), gender (he/she), person (I/you/he), case (objective - him, subjective - he, possessive - his), reflexive (himself)
- Verb: number, gender, person, tense
- Adjective: number, gender
For a short intro to morphology, refer to Introduction to morphology.
Annotation / Tagsets
The Penn
Treebank is an important initiative started in the 1980's. It
describes a set of English sentences with manual annotations
describing the parts-of-speech of all the words and their syntactic
structure. It is an important dataset practically (because many other
works rely on it) but also methodologically, because it demonstrates
a completely empirical method to describe syntax (as opposed to theory-driven).
In this empirical method, the adequacy of syntactic description is achieved when multiple
human annotators who follow detailed guidelines and have followed training agree
on the annotations they provide for a sentence.
The set of tags used for the parts-of-speech in the Penn Treebank is described
in the table site.
A simplified formalism has been introduced recently to describe treebanks and parts of speech called
the universal POS tags.
The definition of the tags is discussed in POS.
The methodological approach of manually annotating text with non-manifest data is of critical importance.
We will review many canonical datasets used heavily in NLP research in the rest of the course.
Sentence: Syntax
We move next to the sentence level. There are various definitions of what is a sentence:
- Graphic: a sequence of words surrounded by delimiters (issues: what are delimiters: period, question mark, exclamation mark, newline)
- Semantic: a complete unit of meaning expressing a proposition (predicate stated on its arguments).
- Syntactic: a toplevel syntactic constituent (not covered by other syntactic elements).
Sentences have an internal structure - they are composed of smaller
parts that have grammatical function. There are different ways to
describe a sentence structure. The structure description captures the
dependencies among the words within the sentence. They reflect
constraints on operations such as:
- Substitution: if one word is replaced by another with different morphological features (e.g., singular->plural), are other words affected by this change? (Agreement).
- Deletion: if one word is removed from the sentence, does the sentence remain syntactically correct? Must other words be deleted as a consequence? (Dependency)
- Movement: if one word is moved within the sentence, must other words follow it?
The 2 major description methods are:
- Constituent-based: a constituent is a group of words, that is assigned a certain category. Basic-level constituents are called phrases.
- Dependency-based: describes a hierarchical structure of dependency among words within the sentence.
Phrases are groups of words that depend on a "central word" that we call the phrase head. Common Phrases include - depending on the part of speech of the head:
- Noun Phrase (NP): two-thirds of the boys
- Adjectival Phrase (AP): very large
- Verb Phrase (VP): walks quickly
- Prepositional Phrases (PP): in the room
One computational problem we will study is that of parsing a linear sequence of words into a constituent tree. The questions to address to model this problem are:
Why is syntactic structure important:
- Structure determines meaning.
- Structure impacts on form (for example, agreement).
- Syntactic structure helps us perform text transformations (simplify a sentence, combine 2 sentences).
For example, consider the following problem: you are given two strings:
S1: John eats
S2: John sleeps
You are asked to build a correct English sentence that combines the two events into one sentence expressing that S2 occurred after S1 in the past.
A possible solution is:
S3: After eating, John slept
Variations of the same task include - given an input string S1, generate the string N1 of the negation of S1, or Q1 - which is a yes-no form of S1, or P1, which is S1 expressed in the past tense etc.
Working directly on strings, such transformations are very difficult to achieve.
One need to know the syntactic structure of the small sentences in order to be able to combine them appropriately.
Descriptive Syntax of the Clause
The syntax for the clause category is the most complex. It can be
described along four perspectives (note: we use here descriptive
terminology from systemic linguistics introduced by M. Halliday
- see for example Introduction to Functional Grammar, Halliday,
1985):
- Transitivity: determines the type of the main process and its participants. (This is often called the "argument structure" of the clause.)
- Circumstantials: determines the structure of modifiers to the predicate and to the clause as a whole.
- Mood: determines whether the clause is finite (declarative, interrogative or relative) or non-finite (imperative, infinitive, participial).
For finite moods, tense and person are specified. For non-finite, they are not.
- Voice: active, passive, causative etc.
The transitivity system determines what participants contribute to the meaning of the clause - when the clause is viewed as a description of an event or relation in the world.
Semantically, a clause is a description of a process - a generic term that can refer to either an event or a relation.
Participants are the constituents within the clause that satisfy the following linguistic criteria:
- They can surface as subject in one syntactic alternation of the clause.
For example:
- John gives Mary a book.
- Mary is given a book by John.
- A book is given to Mary by John.
This indicates that John, Mary, and a book are participants in the clauses.
- They cannot be moved around in the clause without affecting the other constituents.
For example:
- John eats a pie.
- * John a pie eats.
- ? A pie John eats. (would need a comma after pie).
Whereas for non-participants, moving is easier:
- John eats a pie on the sofa.
- On the sofa John eats a pie.
- They cannot be omitted from the clause.
For example,
- John uses a car to travel.
- *John uses to travel.
- John uses a car.
NOTE: Each one of these criteria taken alone is not sufficient
to characterize participants, but taken together they have proven
quite reliable.
Semantically, participants correspond to the nuclear roles of the
process. Additional terms can then be added compositionally to modify
the meaning ofthe process or of the predicate (these correspond to
sentence and predicateadjuncts as explained next.
Argument Structure: Lexical properties of the verb
The main verb of a clause determines which participants (arguments)
are required in the clause. Since many verbs often share the same
argument structures, grammars have traditionally defined names to
refer to common argument structures. Such common structures are given
a name (for example: material process) and define names for
each of the mandatory arguments they expect (for example
agent). In systemic grammar, the following figure describes
the most common argument structures in English: 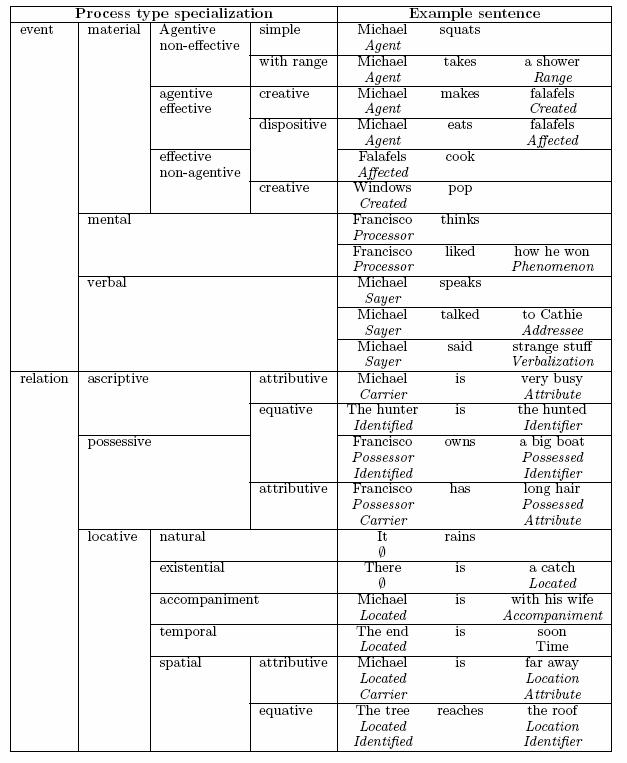 While systemic linguists have developed complex transitivity systems
to account for the structure of the clause, lexicalist approaches to
grammar have developed the notion of subcategorization. The
idea is that in any phrase, the lexical head determines the structure
and order of the subconstituents or dependents in a
dependency-based grammar like Meaning Text Theory (Melcuk and Pertsov,
1987) of the phrase. To capture this dependency, HPSG grammars
describe each lexical item capable of governing arguments with a
feature called the subcategorization list (short name:
subcat). The subcat of a verb is a list of the constituents the
verb expects to form a complete phrase. So forexample, the verb to
deal as in "AI deals with logic" is represented in the lexicon
with a subcat
While systemic linguists have developed complex transitivity systems
to account for the structure of the clause, lexicalist approaches to
grammar have developed the notion of subcategorization. The
idea is that in any phrase, the lexical head determines the structure
and order of the subconstituents or dependents in a
dependency-based grammar like Meaning Text Theory (Melcuk and Pertsov,
1987) of the phrase. To capture this dependency, HPSG grammars
describe each lexical item capable of governing arguments with a
feature called the subcategorization list (short name:
subcat). The subcat of a verb is a list of the constituents the
verb expects to form a complete phrase. So forexample, the verb to
deal as in "AI deals with logic" is represented in the lexicon
with a subcat deal[Subcat( [ NP ] [ PP : with ])]
which
indicates that to produce a clause headed by this verb, one must find
an NP and a PP headed by the preposition with.
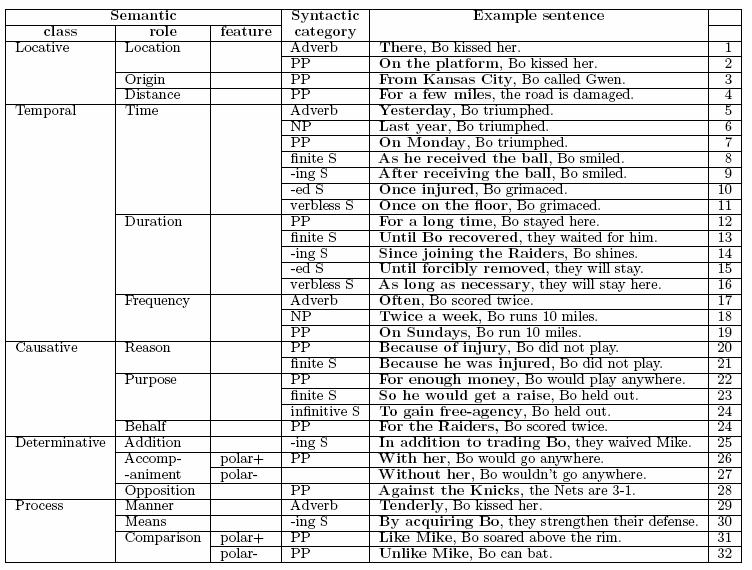
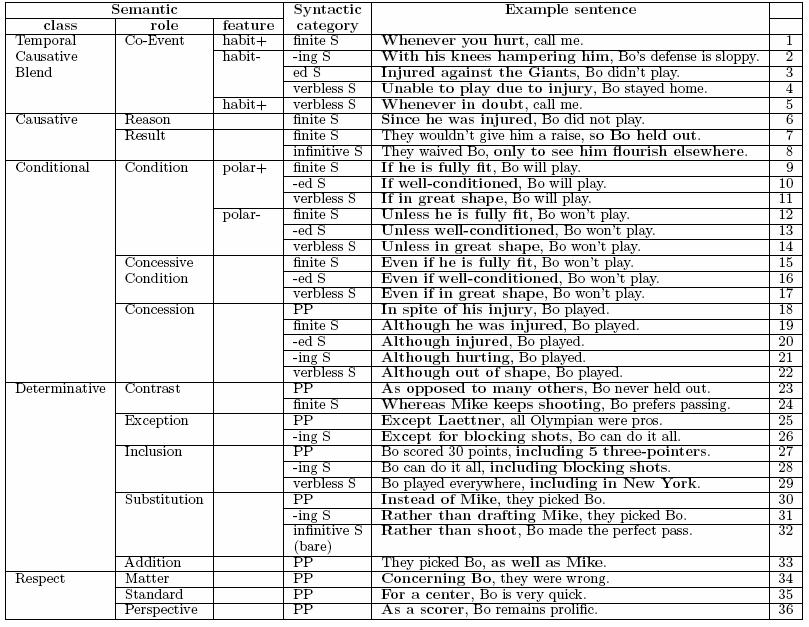
Adjuncts and Disjuncts
Constituents in the clause which are not participants, are classified
in terms of their "distance" from the verb. The three levels
are called predicate adjuncts, sentence adjuncts and
disjuncts. These are the three types of circumstantials.
There following tables give examples of each of these circumstantials:
- Predicate Adjuncts:
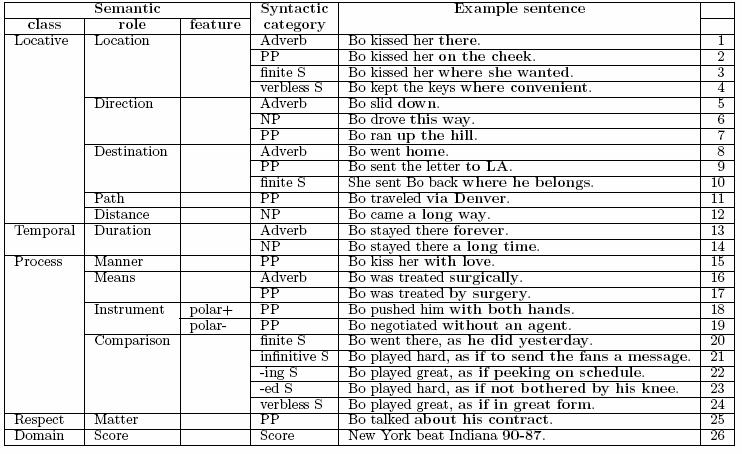
- Sentence Adjuncts:
- Disjuncts:
The Mood of Clauses
The various options for the mood of clauses in English are summarized in this table: 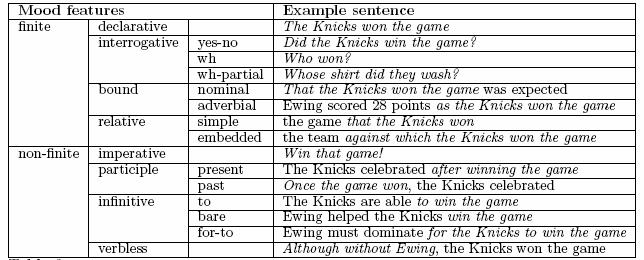
Noun Phrase
Noun phrases in English have a strict syntactic structure - composed
of a sequence of slots, each slot can be filled by constituents of
specific categories. 
Last modified 28 Oct 2016