ti = y(xi) + Normal(mu, sigma) where the xi values are equi-distant on the [0,1] segment (that is, x1 = 0, x2=1/N-1, x3=2/N-1..., xN = 1.0) mu = 0.0 sigma = 0.03 y(x) = sin(2Πx)Our objective will be to "learn" the function y from the noisy dataset we generate. The function generateDataset(N, f, sigma) should return a tuple with the 2 vectors x and t. Draw the plot (scatterplot) of (x,t) using matplotlib for N=50. Look at the documentation of the numpy.random.normal function in Numpy for an example of usage. Look at the definition of the function numpy.linspace to generate your dataset.
Note: a useful property of Numpy arrays is that you can apply a function to a Numpy array as follows:
import math import numpy as np def s(x): return x**2 def f(x): return math.sin(2 * math.pi * x) vf = np.vectorize(f) # Create a vectorized version of f z = np.array([1,2,3,4]) sz = s(z) # For simple functions, you can apply to an array sz.shape # Same dimension as z (4) fz = vf(z) # Must use the vectorized version of f fz.shape
y(x) = w0 + w1x + w2x2 + ... + wMxMOur objective is to estimate the vector w = (w0...wM) from the dataset (x, t). We first attempt to solve this regression task by optimizing the square error function (this method is called least squares:
Define: E(w) = 1/2Σi(y(xi) - ti)2
= 1/2Σi(Σkwkxik - ti)2
If t = (t1, ..., tN), then define the design matrix to be the matrix Φ such that Φnm = xnm = Φm(xn).
We want to minimize the error function, and, therefore, look for a solution to the linear system of equations:
dE/dwk = 0 for k = 0..MWhen we work out the partial derivations, we find that the solution to the following system gives us the optimal value wLS given (x, t):
wLS = (ΦTΦ)-1ΦTt (Note: Φ is a matrix of dimension NxM, w is a vector of dimension M and t is a vector of dimension N.)Here is how you write this type of matrix operations in Python using the Numpy library:
import numpy as np import scipy.linalg t = np.array([1,2,3,4]) # This is a vector of dim 4 t.shape phi = np.array([[1,1],[2,4],[3,3],[2,4]]) # This is a 4x2 matrix phi.shape prod = np.dot(phi.T, phi) # prod is a 2x2 matrix prod.shape i = np.linalg.inv(prod) # i is a 2x2 matrix i.shape m = np.dot(i, phi.T) # m is a 2x4 matrix m.shape w = np.dot(m, t) # w is a vector of dim 2 w.shapeImplement a method OptimizeLS(x, t, M) which given the dataset (x, t) returns the optimal polynomial of degree M that approximates the dataset according the least squares objective. Plot the learned polynomial w*M(xi) and the real function sin(x) for a dataset of size N=10 and M=1,3,5,10.
Define EPLS(w) = E(w) + λEW(w)
Where EPLS is called the penalized least-squares function of w
and EW is the penalty function.
We will use a standard penalty function:
EW(w) = 1/2 wT.w = 1/2 Σm=1..Mwm2
When we work out the partial derivatives of the minimization problem, we find in closed form, that the solution to the
penalized least-squares is:
wPLS = (ΦTΦ + λI)-1ΦTtλ is called a hyper-parameter (that is, a parameter which influences the value of the model's parameters w). Its role is to balance the influence of how well the function fits the dataset (as in the least-squares model) and how smooth it is. Write a function optimizePLS(x, t, M, lambda) which returns the optimal parameters wPLS given M and lambda. We want to optimize the value of λ. The way to optimize is to use a validation set in addition to our training set. To construct a validation set, we will extend our synthetic dataset construction function to return 3 samples: one for training, one for validation and one for testing. Write a function generateDataset3(N, f, sigma) which returns 3 pairs of vectors of size N each, (xtest, ttest), (xvalidate, tvalidate) and (xtrain, ttrain). The target values are generated as above with Gaussian noise N(0, sigma). Look at the documentation of the function numpy.random.shuffle() as a way to generate 3 subsets of size N from the list of points generated by linspace. Given the synthetic dataset, optimize for the value of λ by varying the value of log(λ) from -20 to 5 on the validation set. Draw the plot of the normalized error of the model for the training, validation and test for the case of N = 10 and the case of N=100. The normalized error of the model is defined as:
NEw(x, t) = 1/N [Σi=1..N[ti - Σm=1..Mwmxim]2]1/2Write the function optimizePLS(xt, tt, xv, tv, M) which selects the best value λ given a dataset for training (xt, tt) and a validation test (xv, tv). Describe your conclusion from this plot.
tn = y(xn; w) + εnWe now model the distribution of εn as a probabilistic model:
εn ~ N(0, σ2) since tn = y(xn; w) + εn: p(tn | xn, w, σ2) = N(y(xn; w), σ2)We now assume that the observed data points in the dataset are all drawn in an independent manner (iid), we can then express the likelihood of the whole dataset:
p(t | x,w,σ2) = ∏n=1..Np(tn | xn, w, σ2)
= ∏n=1..N(2Πσ2)-1/2exp[-{tn - y(xn, w)}2 / 2σ2]
We consider this likelihood as a function of the parameters (w and σ) given a dataset (t, x).
If we consider the log-likelihood (which is easier to optimize because we have to derive a sum instead of a product), we get:
-log p(t | w, σ2) = N/2 log(2Πσ2) + 1/2σ2Σn=1..N{tn - y(xn;w)}2
We see that optimizing the log-likelihood of the dataset is equivalent
to minimizing the error function of the least-squares method. That is
to say, the least-squares method is understood as the maximum
likelihood estimator of the probabilistic model we just developed, which produces the values wML = wLS.
We can also optimize this model with respect to the second parameter σ2 which, when we work out the derivation and the solution of the equation, yields:
σ2ML = 1/N Σn=1..N{y(xn, wML) - tn}2
Given wML and σ2ML, we can now compute the predictive distribution, which gives us the probability distribution
of the values of t given an input variable x:
p(t | x, wML, σ2ML) = N(t | y(x,wML), σ2ML)This is a richer model than the least-squares model studied above, because it not only estimates the most-likely value t given x, but also the precision of this prediction given the dataset. This precision can be used to construct a confidence interval around t. We further extend the probabilistic model by considering a Bayesian approach to the estimation of this probabilistic model instead of the maximum likelihood estimator (which is known to overfit the dataset). We choose a prior over the possible values of w which we will, for convenience reasons, select to be of a normal form (this is a conjugate prior as explained in our review of basic probabilities):
p(w | α) = ∏m=0..M(α / 2Π)1/2 exp{-α/2 wm2}
= N(w | 0, 1/αI)
This prior distribution expresses our degree of belief over the values that w can take.
In this distribution, α plays the role of a hyper-parameter (similar to λ in the regularization model above).
The Bayesian approach consists of applying Bayes rule to the estimation task of the posterior distribution given the dataset:
p(w | t, α, σ2) = likelihood . prior / normalizing-factor
= p(t | w, σ2)p(w | α) / p(t | α, σ2)
Since we wisely chose a conjugate prior for our distribution over w, we can compute the posterior analytically:
p(w | x, t, α, σ2) = N(μ, Σ) where Φ being the design matrix as above: μ = (ΦTΦ + σ2αI)-1ΦTt Σ = σ2(ΦTΦ + σ2αI)-1Given this approach, instead of learning a single point estimate of w as in the least-squares and penalized least-squares methods above, we have inferred a distribution over all possible values of w given the dataset. In other words, we have updated our belief about w from the prior (which does not include any information about the dataset) using new information derived from the observed dataset. We can determine w by maximizing the posterior distribution over w given the dataset and the prior belief. This approach is called the maximum posterior (usually written MAP). If we solve the MAP given our selection of the normal conjugate prior, we obtain that the posterior reaches its maximum on the minimum of the following function of w:
1/2σ2Σn=1..N{y(xn, w) - tn}2 + α/2wTw
We find thus that wMAP is in fact the same as the solution of the penalized least-squares method for λ = α σ2.
A fully Bayesian approach, however, does not look for point-estimators of parameters like w. Instead, we are interested in the predictive distribution
p(t | x, x, t). The Bayesian approach consists of marginalizing the predictive distribution over all possible values of the parameters:
p(t | x, x, t) = ∫ p(t|x, w)p(w | x, t) dw(For simplicity, we have hidden the dependency on the hyper-parameters α and σ in this formula.) On this simple case, with a simple normal distribution and normal prior over w, we can solve this integral analytically, and we obtain:
p(t | x, x, t) = N(t | m(x), s2(x)) where the mean and variance are: m(x) = 1/σ2 Φ(x)TS Σn=1..NΦ(xn)tn s2(x) = σ2 + Φ(x)TSΦ(x) S-1 = αI + 1/σ2 Σn=1..NΦ(xn)Φ(xn)T Φ(x) = (Φ0(x) ... ΦM(x))T = (1 x x2 ... xM)TNote that the mean and the variance of this predictive distribution depend on x. Your task: write a function bayesianEstimator(x, t, M, alpha, sigma2) which given the dataset (x, t) of size N, and the parameters M, alpha, and sigma2 (the variance), returns a tuple of 2 functions (m(x) var(x)) which are the mean and variance of the predictive distribution inferred from the dataset, based on the parameters and the normal prior over w. As you can see, in the Bayesian approach, we do not learn an optimal value for the parameter w, but instead, marginalize out this parameter and directly learn the predictive distribution. Note that in Python, a function can return a function (like in Scheme) using the following syntax:
def adder(x):
return lambda(y): x+y
a2 = adder(2)
print a2(3) // prints 5
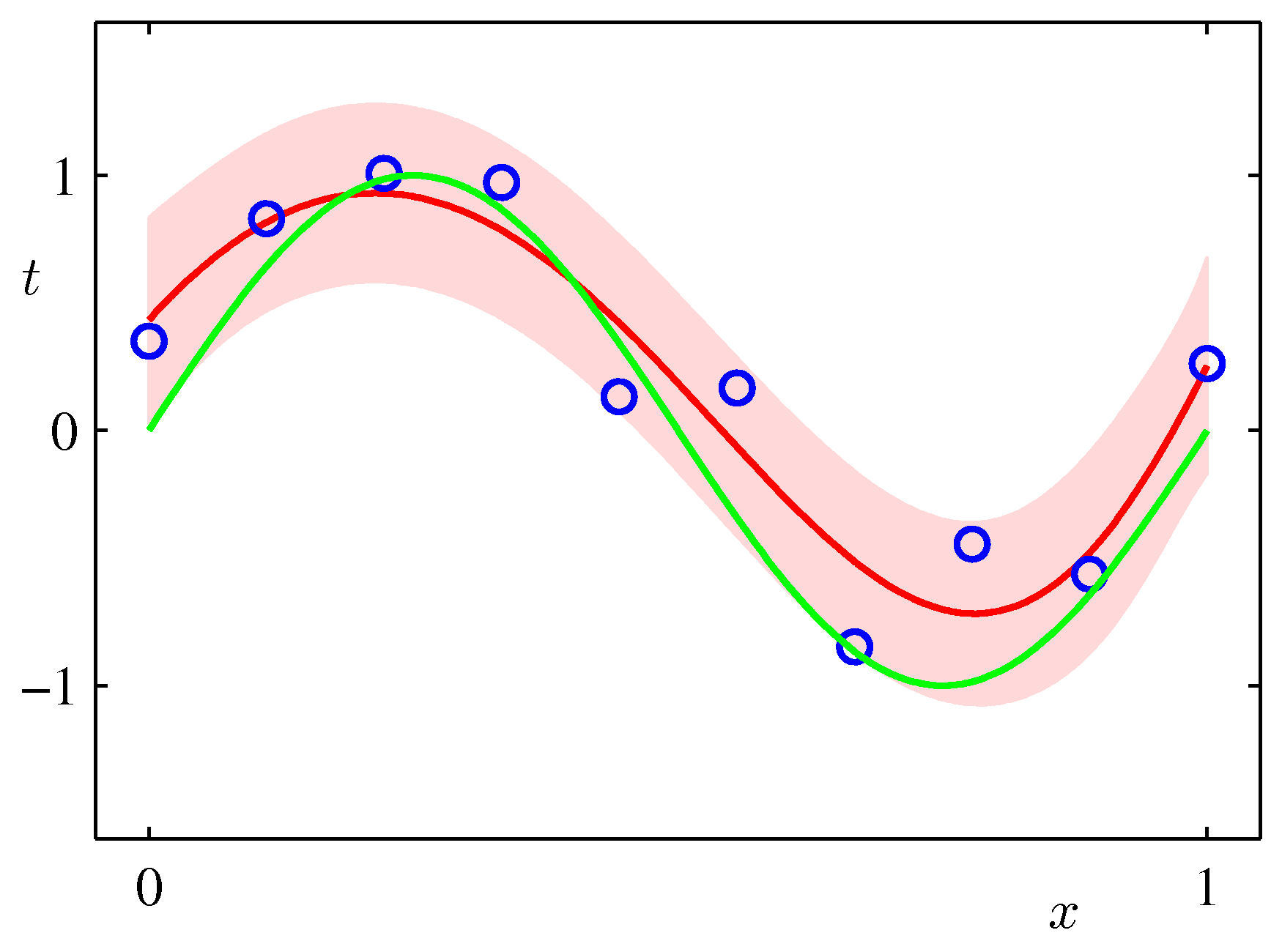
Draw the plot of the original function y = sin(x) over the range [0..1], the mean of the predictive distribution m(x) and the confidence interval
(m(x) - var(x)1/2) and (m(x) + var(x)1/2) (that is, one standard deviation around each predicted point) for the values:
alpha = 0.005 sigma2 = 1/11.1 M = 9over a synthetic dataset of size N=10 and N=100. The plot should look similar to the Figure below (from Bishop p.32).
from nltk.corpus import movie_reviews
negative = movie_reviews.fileids('neg')
positive = movie_reviews.fileids('pos')
movie_reviews.words(fileids=['neg/cv000_29416.txt'])
bag_of_words(movie_reviews.words(fileids=['neg/cv000_29416.txt'])) --> Return a list of feature vectors for the documentWrite a function evaluate_features(feature_extractor, N) which learns a NaiveBayes classifier on the movie_reviews dataset as follows:
from nltk.corpus import stopwords
stopset = set(stopwords.words('english'))
def stopword_remover(words):
return dict([(word, True) for word in words if word not in stopset])
Write a new feature extractor over the movie reviews dataset which keeps only the top-K most frequent words across the whole dataset
and filters out stop words. Since K is a parameter, define a higher-order function: make_topK_non_stopword_extractor(K, stopwords).
Evaluate this new feature extractor:
extractor = make_topK_non_stop_word_extractor(10000, stopset) classifier = evaluate_features(extractor, 10)Compare the behavior of this new feature extractor with the baseline bag of words. Try to optimize the value of the parameter K to learn a good classifier. Do you see a predictable behavior of the accuracy and other metrics of the classifier as K varies as a function of the size of the total vocabulary in the training set W. Draw a plot of accuracy vs. K/W. Identify documents which are classified differently by the 2 classifiers and report new_positives and new_negatives. Explain the differences you observe.
Most Informative Features
magnificent = True pos : neg = 15.0 : 1.0
outstanding = True pos : neg = 13.6 : 1.0
insulting = True neg : pos = 13.0 : 1.0
vulnerable = True pos : neg = 12.3 : 1.0
ludicrous = True neg : pos = 11.8 : 1.0
uninvolving = True neg : pos = 11.7 : 1.0
avoids = True pos : neg = 11.7 : 1.0
astounding = True pos : neg = 10.3 : 1.0
fascination = True pos : neg = 10.3 : 1.0
idiotic = True neg : pos = 9.8 : 1.0
We will try to filter the features by keeping only those that are tagged by a "promising part of speech tag".
Use the best part of speech tagger you have trained in Assignment 1 on the Brown corpus, and apply it to the
movie_reviews dataset. Make sure you train your classifier on lower case text only, since the movie reviews
dataset contains only lower case text.
Write a feature extractor constructor make_pos_extractor which constructs a feature extractor that filters words by their POS.
The extracted features are words that are tagged by one of the requested tags.
extractor = make_pos_extractor(['NN', 'VBG', 'ADJ', 'ADV']) classifier = evaluate_features(extractor, 10)Identify a good set of POS tags that give good results. Explain your observation.
import itertools
from nltk.collocations import BigramCollocationFinder
from nltk.metrics import BigramAssocMeasures
score = BigramAssocMeasures.chi_sq # chi square measure of strength
def strong_bigrams(words, score_fn, n):
bigram_finder = BigramCollocationFinder.from_words(words)
bigrams = bigram_finder.nbest(score_fn, n)
return [bigram for bigram in itertools.chain(words, bigrams)]
Use this method to extract good bigrams over the training dataset and compare this with the baselines listed above.