Statistical Constituent-based Parsing
This lecture discusses computational methods to perform practical statistical syntactic parsing of sentences in free text into
a constituent-based syntactic representation.
If you want to go for a wonderful in-depth review of this material, follow the whole seven lectures in Chris Manning's
Seven Lectures on Statistical Parsing from 2007.
Where We Stand
In the previous lecture, we reviewed how to encode constituent trees (the tree datastructure),
grammars (CFGs), and a fast polynomial algorithm to parse a sequence of words into a tree given a CFG: the CYK algorithm.
Since CYK requires the grammar to be in Chomsky Normal Form (CNF), we also discussed an algorithm to transform a CFG into
an equivalent CNF grammar.
We now turn to a corpus-based machine-learning method to derive a parser from a treebank.
Treebank
To develop a constituent-based parser, we need a grammar.
We can ask a language expert to prepare a CFG grammar. It turns out that it is extremely difficult to write large coverage grammars.
Large teams have tried and failed.
Instead, we can try to learn a grammar from examples. As usual, we can try supervised or unsupervised machine learning.
We will start and investigate supervised learning methods for parsing -- that is, we require a set of pairs (sentence, parse-tree).
Such a set of annotated examples is called a treebank.
Treebanks are created by linguists to describe the syntactic structure of naturally occurring sentences.
The Penn Treebank is the most famous treebank used in the field.
It contains about 50,000 sentences (covering about 3M words). The process of creating a treebank is described
in this paper: Building a Large Annotated Corpus of English: The Penn Treebank,
by Mitchell Marcus, Beatrice Santorini and Mary Ann Marcinkiewicz, Computational Linguistics, 1993.
When creating a treebank, the key objective is to obtain a consistent method to annotate sentences. Consistency is achieved by testing for
agreement among annotators: if 3 different annotators create the same syntactic tree for a sentence, then we can assume this tree reflects
a well understood process. The treebank construction process consists of asking annotators to propose a tree, comparing the trees and whenever
disagreements are detected, to define guidelines to resolve them.
The Penn Treebank Guidelines have been collected into a 300 page document ("Bracketing Guidelines for the Penn Treebank", 1995).
The Penn Treebank annotations are encoded in a Lisp-like notation to encode trees:
Tree for the sentence: "Had Casey thrown the ball harder, it would have reached home plate in time."
(S (SBAR-ADV (SINV had
(NP-SBJ Casey)
(VP thrown
(NP the ball)
(ADVP-MNR harder))))
,
(NP-SBJ it)
(VP would
(VP have
(VP reached
(NP home plate)
(PP-TMP in
(NP time))))))
The tagset used to describe the syntactic categories is formed of:
- Part of speech: for the nodes immediately above the words (pre-terminals).
- Syntactic categories: S, NP, VP, PP, ADVP
- Annotated syntactic categories: for example, NP-SBJ is an NP in subject position.
Deriving a grammar from a treebank
Once given a treebank, we can "learn" a grammar that fits the observed treebank.
To perform this operation, called "grammar induction", we must first decide which
grammar model we want to derive.
The Chomsky Hierarchy
By grammar model, we refer to the family of grammars we are interested in learning.
Chomsky derived in 1956 a hierarchy of formal grammars of varying expressive power
and parsing complexity, known as the Chomsky Hierarchy.
When we decide to induce a grammar from a treebank, we must decide which level of this hierarchy we aim for.
All grammars in the hierarchy are defined as a tuple: (T, N, P, S) where:
- T: a set of terminal symbols (in our case, the words of the language).
- N: a set of non-terminal symbols (in our case, part of speech and syntactic categories)
- P: a set of productions (also known as rewriting rules)
- S: a designated starting symbol in N.
The differences in the levels of the hierarchy correspond to the allowed forms of the rules.
The hierarchy includes the following levels:
- Unrestricted grammars: rules can be of any form (u → v)
- Context sensitive grammars: rules of the form (uAv → uwv)
- Context free grammars: rules of the form (A → u)
- Regular languages: rules of the form (A → a) and (A → aB)
(where u, v refer to any sequence of non-terminal and terminal symbols, A and B refer to non-terminal symbols and a refers to terminal symbols).
This hierarchy defines more and more expressive grammars (least expressive is "regular", most expressive is "unrestricted").
But more expressive grammars require more complex parsing methods:
- Unrestricted grammars: parsing is undecidable
- Context sensitive grammars: parsing is exponential
- Context free grammars: parsing is polynomial
- Regular languages: parsing is linear
For our purposes, we decide to use Context Free Grammars. This is an empirical decision.
CFGs and Natural Languages
Is it reasonable to use CFGs to model natural language syntax?
Characteristics of natural language syntax such as agreement and
pronoun co-reference constraints cannot be modeled using context free
grammars. On the other hand, the skeleton recursive structure of
natural language sentences can be modeled using CFGs.
Theoretically, any finite language can be modeled by a trivial CFG (one non-terminal per sentence).
But this trivial grammar is really not interesting. Similarly, assume there is agreement in
a language between subject and verb based on number (if subject is singular, verb must be singular,
same for plural). Then a basic CFG rule that only describes the structure of the constituents
can be expanded into a more complex CFG that also captures agreement:
S → NP VP
can be replaced by:
S → S-singular
S → S-plural
S-singular → NP-singular VP-singular
S-plural → NP-plural VP-plural
In other words, the counter-claims that a natural language phenomenon is not context free can be addressed by
creating a more complex CFG that captures the observed context dependencies through higher number of categories
and rules.
We are interested in inducing from examples the "most interesting" and "least complex" CFG that can account for the data.
To model this notion of what is an interesting and what is a complex CFG, we will intuitively design a metric, which we
will call the "Description Length" that measures how complex a CFG is: we will assume that the number of non-terminals
and the number of rules contribute to this metric. Our goal is, therefore, to induce a CFG with Minimum Description Length
(MDL) that explains the observed treebank.
From trees to productions
The first method we use to derive a CFG from a treebank is to derive a production (a rule) for each interior node
observed in the treebank. This method is illustrated in this figure:
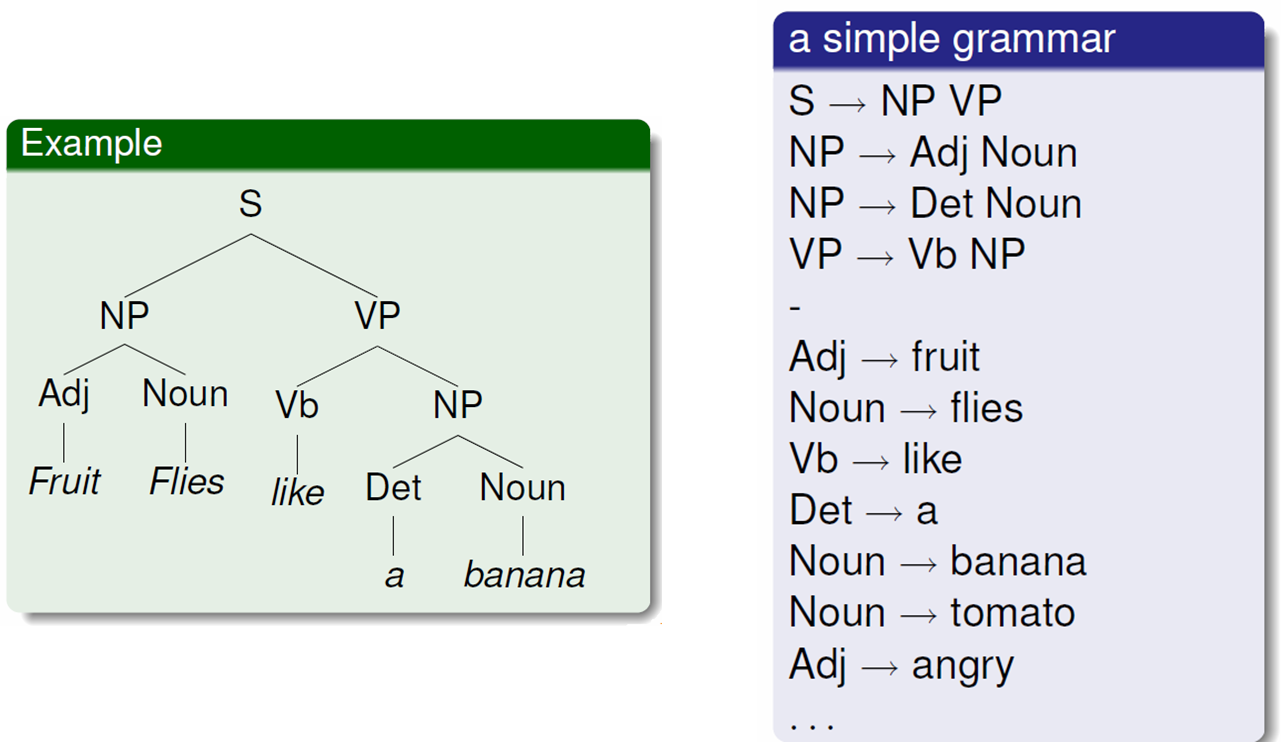 For example, since in the tree we observe a node NP that covers nodes Adj and Noun, we derive a rule (NP → Adj Noun).
Since there are many words in the treebank (about 3M), and for a sentence with about 20 words there can be about once to twice
as many interior nodes, we will get a very large number of productions generated from the treebank. We will observe that many
of these rules are in fact repeated many times, and a few occur very rarely in the corpus (in the usual long tail distribution
that is characteristic of many corpus statistics). In fact, for a corpus of about 1M words, we find about 5000 distinct rules
and about 100 non-terminal symbols. (These figures give us an idea of the description length of this first model.)
For example, since in the tree we observe a node NP that covers nodes Adj and Noun, we derive a rule (NP → Adj Noun).
Since there are many words in the treebank (about 3M), and for a sentence with about 20 words there can be about once to twice
as many interior nodes, we will get a very large number of productions generated from the treebank. We will observe that many
of these rules are in fact repeated many times, and a few occur very rarely in the corpus (in the usual long tail distribution
that is characteristic of many corpus statistics). In fact, for a corpus of about 1M words, we find about 5000 distinct rules
and about 100 non-terminal symbols. (These figures give us an idea of the description length of this first model.)
Dealing with Words
When analyzing corpus data, we observe that the rate of "unknown words" remains high even with very large corpora: that is,
if we sample 1M words from a corpus, list all the observed words, then sample another 1M words, we will find that more than
5% of the words in the second part of the corpus were never seen before in the first half. Even if we remember all the words
observed in the 2M word corpus, and sample another 1M words, we will find that 5% of the new words are "unknown". This rate
of unknown words remains high until we reach "Web-scale" corpora (several hundreds of millions of words).
Compared to these dimensions, syntactic treebanks remain necessarily small (because of the high cost required to produce
reliable syntactic annotations). To avoid the problem of learning how to cope with the many unknown words and dealing with
the large number of known words (hundreds of thousands of words in the vocabulary) using the statistical methods we will
review below, we will rely on the results of a pre-processing stage: a part-of-speech tagger as reviewed in Chapter 2.
Our assumptions in the following are therefore:
- Natural language text is segmented into "clean" sentences.
- Sentences are split into clean words.
- Sentences are tagged with parts of speech tags in a reliable manner.
Each of these steps (sentence and word segmentation, tagging) are much easier in English than in other languages
with rich morphology (such as Hebrew) or un-segmented words (Chinese, Japanese). Even in English, these steps
introduce some level of noise: for example, in English, the best tagging reaches 98% accuracy, but this depends
on the domain of the text and can go lower.
To achieve sentence segmentation, nltk includes a
statistical
sentence segmentation module, based on the Punkt sentence
segmenter (Kiss and Strunk: Unsupervised multilingual sentence boundary detection,
in Computational Linguistics, volume 32, pages 485–525, 2006).
Here is an example of how to segment text:
>>> sent_tokenizer=nltk.data.load('tokenizers/punkt/english.pickle')
>>> text = nltk.corpus.gutenberg.raw('chesterton-thursday.txt')
>>> sents = sent_tokenizer.tokenize(text)
>>> pprint.pprint(sents[171:181])
['"Nonsense!',
'" said Gregory, who was very rational when anyone else\nattempted paradox.',
'"Why do all the clerks and navvies in the\nrailway trains look so sad and tired,...',
'I will\ntell you.',
'It is because they know that the train is going right.',
'It\nis because they know that whatever place they have taken a ticket\nfor that ...',
'It is because after they have\npassed Sloane Square they know that the next stat...',
'Oh, their wild rapture!',
'oh,\ntheir eyes like stars and their souls again in Eden, if the next\nstation w...'
'"\n\n"It is you who are unpoetical," replied the poet Syme.']
This example illustrates the complexity of sentence segmentation: reported speech, new lines, acronyms are all confusing.
We will see another method to learn how to segment sentence in the next chapter on classification.
You can read a short intro on this in NLTK's
Chapter 6.2.
Dealing with Ambiguity
Once we induce a simple CFG from the treebank, we can apply the CYK algorithm and parse new, unseen sentences.
How well does that work?
We have a first problem that CYK only works on grammars that are in Chomsky Normal Form (CNF).
We could translate the induced grammar into CNF (there is a procedure to perform this operation).
But it is easier to instead convert the trees in the treebank to CNF and then induce the grammar from the
transformed trees. NLTK includes a module to perform such tree transformations in the
treetransforms module.
The grammar we learn on the transformed trees is "equivalent" to the one we would learn on the original trees,
because the transformations we apply are "reversible" (look at methods chomsky_normal_form and un_chomsky_normal_form).
The procedure consists of:
Training:
Original Treebank → CFN Treebank → CNF Grammar
Testing:
Parse Sentence with CNF Grammar → CNF Tree → un_CNF(tree) → Tree similar to the original grammar
We will find that the resulting grammar has 2 issues:
- It vastly overgenerates: it can generate many sentences which are really not "grammatical" to the ears of English speakers.
- It is highly ambiguous: it will generate many different trees for the same sentence.
The first problem is not so much an issue for us: we will use the parser to parse real sentences, and we will not use
our model to distinguish "real" sentences from "bad" ones.
The second problem is a real issue: we do not want hundreds of parse trees for a single sentence; we want the "best possible"
tree -- the one that best explains the observed sentence. We could go for a few trees (say the top K trees) in case the parser
feels there is real ambiguity and we expect another module later to disambiguate based on semantic or discourse level knowledge.
But we certainly do not want all possible parses without any ranking. How can we rank the trees the grammar produces?
Probabilistic CFG
In order to decide which tree is the most likely for a given sentence,
we will extend the CFG formalism with a probabilistic model: PCFG. In
PCFG, each rule is associated to a probability, so that when we look
at all the rules with the same left-hand-side non-terminal, the sum of
the probabilities is 1.
X → Y1 Z1 | p1
X → Y2 Z2 | p2
...
X → Yn Zn | pn
Σpi = 1.0
The generative story of a PCFG is the following:
- Start from the start symbol S
- Pick a rule from the possible rewritings of (S → rhsi) according to the distribution pi
- For each non-terminal in the selected rhs, expand it using the same mechanism (pick a rule according to the distribution).
- Repeat until all non-terminals have been expanded to terminal leaves.
Parsing PCFG with CYK
Viterbi
Evaluating a CFG Parser
Independence Assumptions
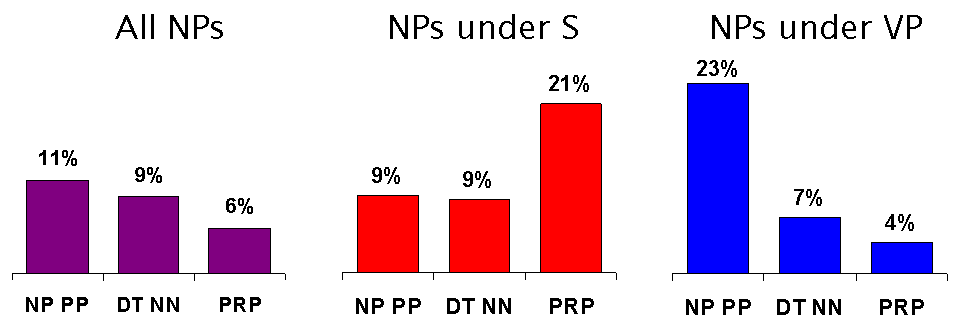
(From Seven Lectures on Statistical Parsing, Chris Manning, Lecture 3).
Last modified March 31st, 2011