make any assumptions about the background and i considered it as unknown.
·
Camera: the video may be taken from a stationary camera or moving camera. In my ·
Lighting: the lighting throw the video may be either fixed or varying. I used a technique that allows a
It can be said that in order to achieve the goal my algorithm is divided into 4 steps:
I will show my results step after step throw an example I chose. The video is a 1.5 seconds
work, I restricted it for a stationary camera.
difference in the lighting throw the video as long as it varies
in a reasonable speed (will be explained later).
Approach and Method
Step 1 - Averaging:
average the frames. Assuming that the background is stationary, doing so allowed me to
locate the object in the next steps.
At the beginning I averaged the entire video frames throw the video into one image that
represents the average. But, later I discovered that it is not a good idea since throw all the
video each pixel color value is changing due to many parameters such as - lighting, noise,
shadows and more. So, i decided to divide the video to a set of adjacent frames and each
"local" set of adjacent frames were averaged separately. This technique allowed a changing
in lightning throw the video without affecting the segmentation.
Another improvement was to average block of pixels into one value and than average
adjacent blocks. I discovered that working in pixel resolution is quite not efficient and not so
accurate.
Step 2 - segregation throw color distribution:
After averaging i found out that in order to identify the object I can use a technique called
color distribution. The idea is simple, for each block compute the absolute difference
between the block values and the corresponding average, for all 3 components (RGB):
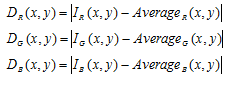
Combine those values into one value that represents the difference:
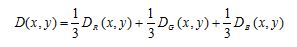
Finally, locate the figure throw thresholding:
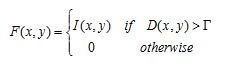
Step 3 - locating object components:
In this stage i had a sketch of the figure I want to segment but it wasn't accurate enough
since there were a lot of noises. So, at this stage i decided that only figures with size bigger
than 24*24 pixels will be considered as object (this parameter is an input to my algorithm
and can be changed). For each frame I found the pixels that fulfill this condition.
Step 4 - "magic wand":
When I got to this stage i hade, for each frame, the blocks that belongs to the object. But, the
frames were divided into blocks so the curves looked not so accurate (like rectangles). Now, i
developed (with an open source I found that I adjusted to my needs) a method that takes
pixel and find all the pixels in the area that correspond to its color. I gave this tool the pixels i
found in the previous stage the output was a binary mask of all the object pixels that were
lost in the previous stages. The final output of my algorithm was (for each frame):
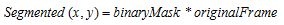
In order to present the output of my algorithm i put together all this frames into an .AVI file
with the figure segregated from the ground (in black).
Results
and it show a man running from one side to the other.

After Averaging (frames 29 - 32 in this case):

After segregation throw color distribution:

Magic wand:

It can be seen that more than 90 percent of the figure is shown. Moreover, there are no
noises in the background.
Some more examples can be in the full report. Also, the full videos are attached.
Conclusions
My goal was achieving good quality segmentation. As we learned in class, segmentation is
subjective and not an easy task. My algorithm take a few parameters such as: threshold for
the figure ground segregation, block size for averaging, another threshold for the magic wand
tool and more. Choosing different values affects directly on the results. Therefore, the
quality is a matter of trial and error and can be changed according to needs.
speed. As faster it moves as it segmented in a higher quality. The object location throw the
video also affects the quality. In order to achieve better result the object need to change his
position throw the video. Otherwise, most of the time he will considered as background.
Also, the size of the figure and the color that composes it may affect the results.