Content-Based Image Retrieval
(CBIR)
By:
Victor Makarenkov
Michael Marcovich
Noam Shemesh
Introduction : Ideas and Goals
Content-based image retrieval, a technique which uses visual contents to search images from large scale image databases according to users' interests, has been an active and fast advancing research area since the 1990s. In our project we concentrated on region-histogram features to retrieve the images according to an example query image supplied by the user.
Let's explain the "region-histogram features".
Histogram is a measure used to describe the image. In simple words it means the distribution of color brightness across the image. The brightness values range in [0..255]. Region based means that the histogram measure is not taken globally for the whole image, but locally for different image regions. This region-histogram features were used as index of the image database.
We implemented a small CBIR system. Our goals were to check how good\bad can the histogram measure serve us to that task. Probably the histogram won't work well in general cases. We want to check which image classifications are better for that. We want to see what improvements can be done on basic histogram comparison to increase results accuracy.
General CBIR system works according to the following schema:

In our CBIR system we implemented all the parts except the one of relevance feedback.
Course of Action
We elaborate the components of the above schema, as they are in our system.
· Query formation by the user: is done using the method of example query. Wherever the user wants to find the image he supplies the image, and the system should return top 5 similar pictures.
· Visual content description: since we using histogram of image, we transform the file of the image to its bitmap representation. That means 2D array where each cell contains a triple with the RGB brightness values for the colors Red,Green,Blue.
·
Feature vectors: In
our system, for generality purposes we assume that the images are of fixed size
200*200 pixels. (If not our system converts them to that size). We use local
histogram values. The image is divided into N * N square areas, and then the
histogram computed in each area.Each area is of size (200/N)*(200/N) pixels
.Each image is represented with N*N length vector where each coordinate is the
histogram in the appropriate area. More precisely: ![]() and
and ![]() .
.
·
Similarity comparison:
for a similarity comparison we used the Minkowski distance. Minkowski distance
between 2 images I and J is denoted as: ![]() while we started our
research when p=2. (Euclidian distance). Using this comparison we measured the
distance for each two images in two levels:
while we started our
research when p=2. (Euclidian distance). Using this comparison we measured the
distance for each two images in two levels:
o Level 1: measure the Minkowski distance between each 2 corresponding histogram regions of the images. To compute the distance in area level – to find each F(i)-F(j).
o Level 2: Summing all the powers of distances from level 1 to form a Minkowski distance at image level with a taking a root of this summation.
· Indexing and retrieval: for all images that are in the databases the feature vector is pre-computed and stored as index in file. When retrieval should be made, the image with the least Minkowski (most similar images) distance between query image and image from database is returned.
Implementation
We implemented our CBIR system in C# using Windows-Forms. The code consists of 4 classes with logic and one GUI class with the main system screen. The database is a list of images stored under folder \database\ and the index (which is pre-computed) is stored as a binary serialization of the feature vectors into a file. The index file is called index.dat. Each time the system is loaded, the index is de-serialized into the main memory, and whenever the search takes place it is ready for comparisons.
Each time the system shuts down – the index (with potentially new entries) is serialized back into the file.
The system presents the top 5 results for the image query. Thus allowing the user to see some possible suggestions.
At the first time the system is installed the user can change the N parameter described above – in order to adjust the division of areas the image is divided to.
The program GUI looks like:

The user can choose the P parameter of minkowski mean and the mode of search in the histogram areas : Regular or weighted (the closer to the center of image – the higher similarity measure – the less the distance between images).
Experiments and results:
We experimented with our system using the following techniques:
· Simple (Global) Histogram.
· Complex (Areas based) Histogram.
· Weighted Areas.
Our first assumption was that the results will improve as we going through these stages. For example we thought that division of image into areas, and using complex histogram measure will improve dramatically the results. The second assumption was that weighted areas, i.e., giving more similarity weight to more central parts of images that are alike. We thought it will give better results for example for passport photographs – when the main part of the image located in its center.
Experiment process:
At the first stage, to check the system we used some "trivial" images to check if we coded the system without bugs. We used images like: blue square at the center of white one, or red circle at the top right corner. In this way we checked that area weighting is working in general. Then we proceeded to the next stage.
We took sets of triples or pairs of similar (took at same place and similar illumination and set of colors) pictures. Our goal was to show that by giving query image it will return similar ones took in analogous way. For example a trip photo (colorful image), party photo (dark illumination), finishing officer's course image (all the soldiers wear same uniform).
We expect that once the image exists at the database – it should be returned first top ranked.
Our Database is :

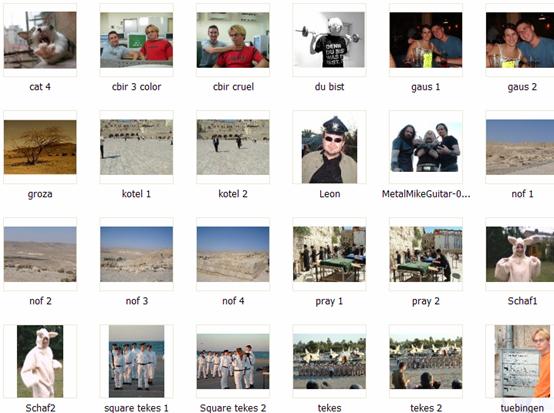
Conclusions:
As we thought at the beginning – Histogram is quite primitive and insufficient way for CBIR purposes. However, with certain image characteristics it may be useful, and works well. For example on the military ceremony and the nature images.
Another important foundation we made is that one of our initial assumptions was wrong. It is that dividing the image into many area , does not always improve the results of retrieval. In case of too many divisions, it degrades the results. The reason for that is that while comparing small parts, that are corresponding between the images and are at fixed place, they can be different. But if the same picture can be shifted, and not be found! The method is not shift invariant!
In some cases , small division (4 areas) did help. For example on the
image of
The "Minkowski distance" that was changed several times during our experiments did not make dramatic changes, but moved some further images close when P is enlarged.
May be used to tuning when similar content image exists, but is not ranked top. Enlarging P in that case can "push" its rank higher.
Download:
References:
·
Dr. Fuhui Long, Dr. Hongjiang
Zhang and Prof. David Dagan Feng.
Content
Based Image Retrieval.
· Dr. Fuhui Long, Dr. Hongjiang Zhang and Prof. David Dagan Feng
An Effective Region-Based Image Retrieval Framework
·
Yossi Rubner, Carlo Tomasi, and
Leonidas J. Guibas The
Earth Mover's Distance as a Metric for Image Retrieval